LERF-TOGO
Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping
UC Berkeley
CORL 2023 (Best Paper Finalist)
TL;DR: LERF-TOGO uses CLIP and DINO features for language-specified tasks performing zero-shot semantic grasping.
Experiments
Abstract
Grasping objects by a specific part is often crucial for safety and for executing downstream tasks. Yet, learning-based grasp planners lack this behavior unless they are trained on specific object part data, making it a significant challenge to scale object diversity. Instead, we propose LERF-TOGO, which uses vision-language models zero-shot to output a grasp distribution over an object given a natural language query. To accomplish this, we first reconstruct a Language Embedded Radiance Field (LERF) of the scene, which distills CLIP embeddings into a multi-scale 3D language field queryable with text. However, LERF has no sense of objectness, meaning its relevancy outputs often return incomplete activations over an object which are insufficient for subsequent part queries. LERF-TOGO mitigates this lack of spatial grouping by extracting a 3D object mask via DINO features, then conditionally querying LERF on this mask to obtain a grasp distribution over the object.
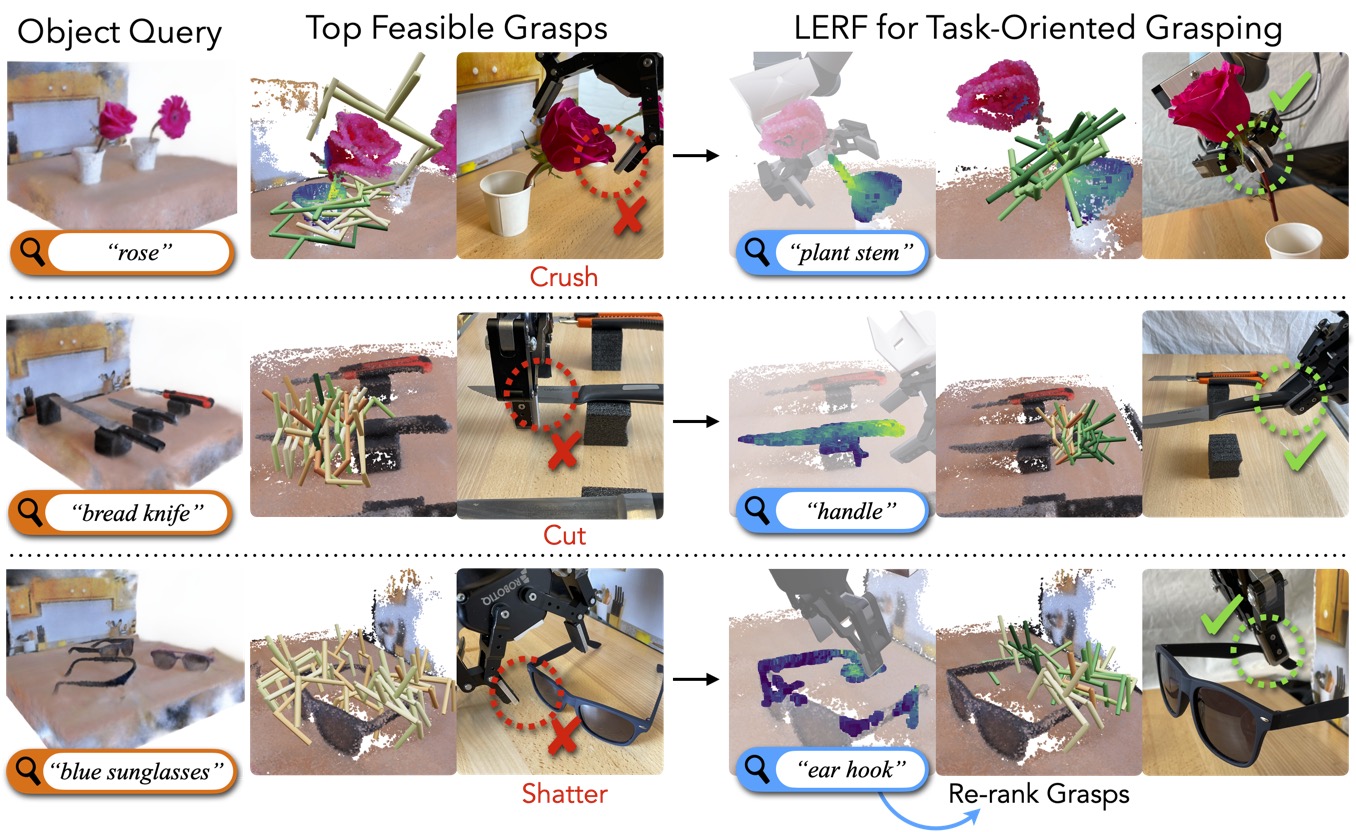
Results
Click the thumbnails below to load the interactive scenes, use SEM/GEO to toggle between Semantic and Geometric grasps.
This in-browser interactive 3D scene is enabled by Viser
How it works
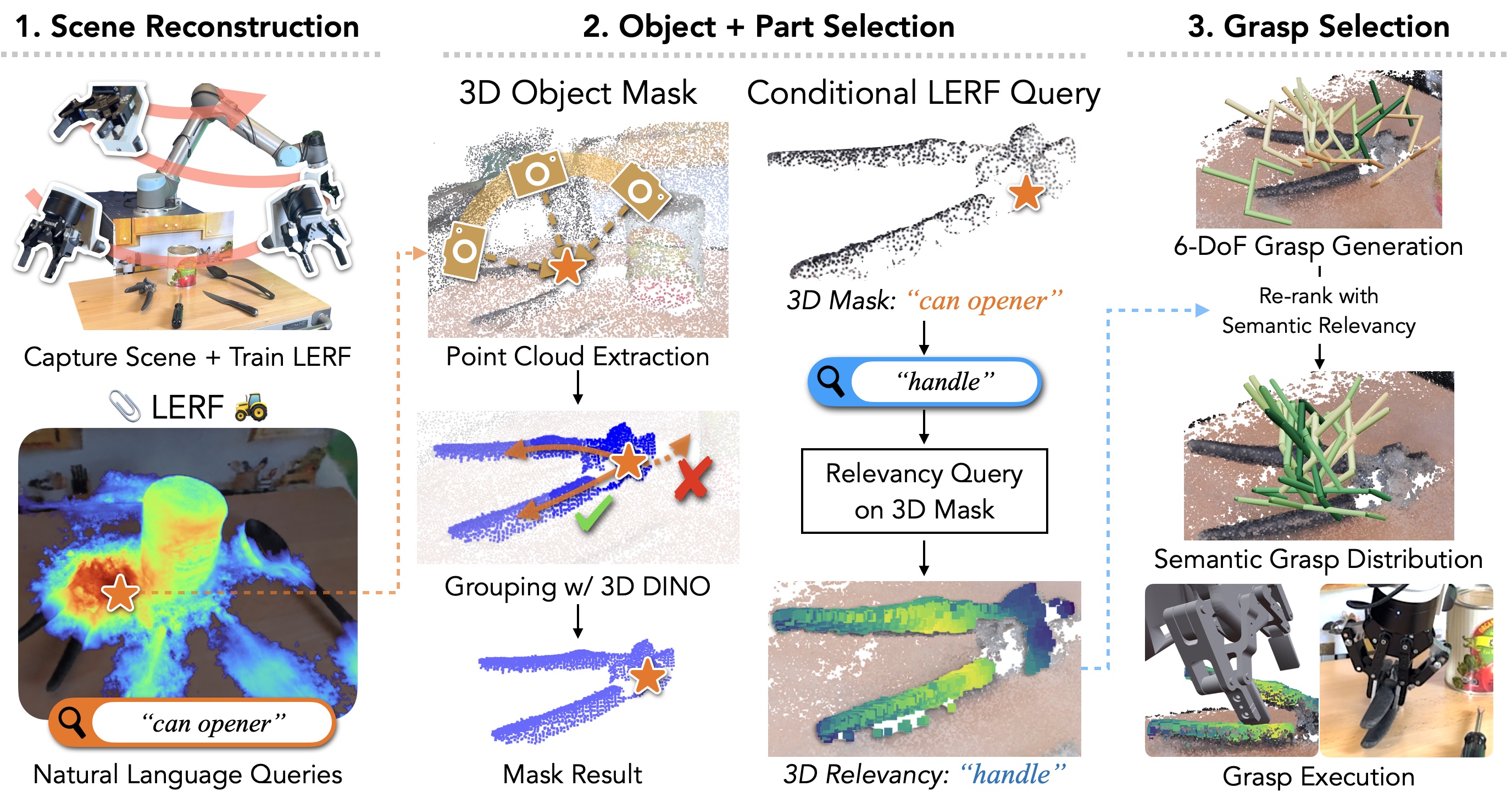
Given an object and object part query, LERF-TOGO outputs a ranking of viable grasps on the object part. First, LERF generates a 3D relevancy map that highlights the relevant parts of the scene. Second, a 3D object mask is generated using the LERF relevancy for the object query and DINO based semantic grouping. Third, a 3D part relevancy map is generated with a conditional LERF query over the object part query and the 3D object mask. The part relevancy map is used to produce a semantic grasp distribution.
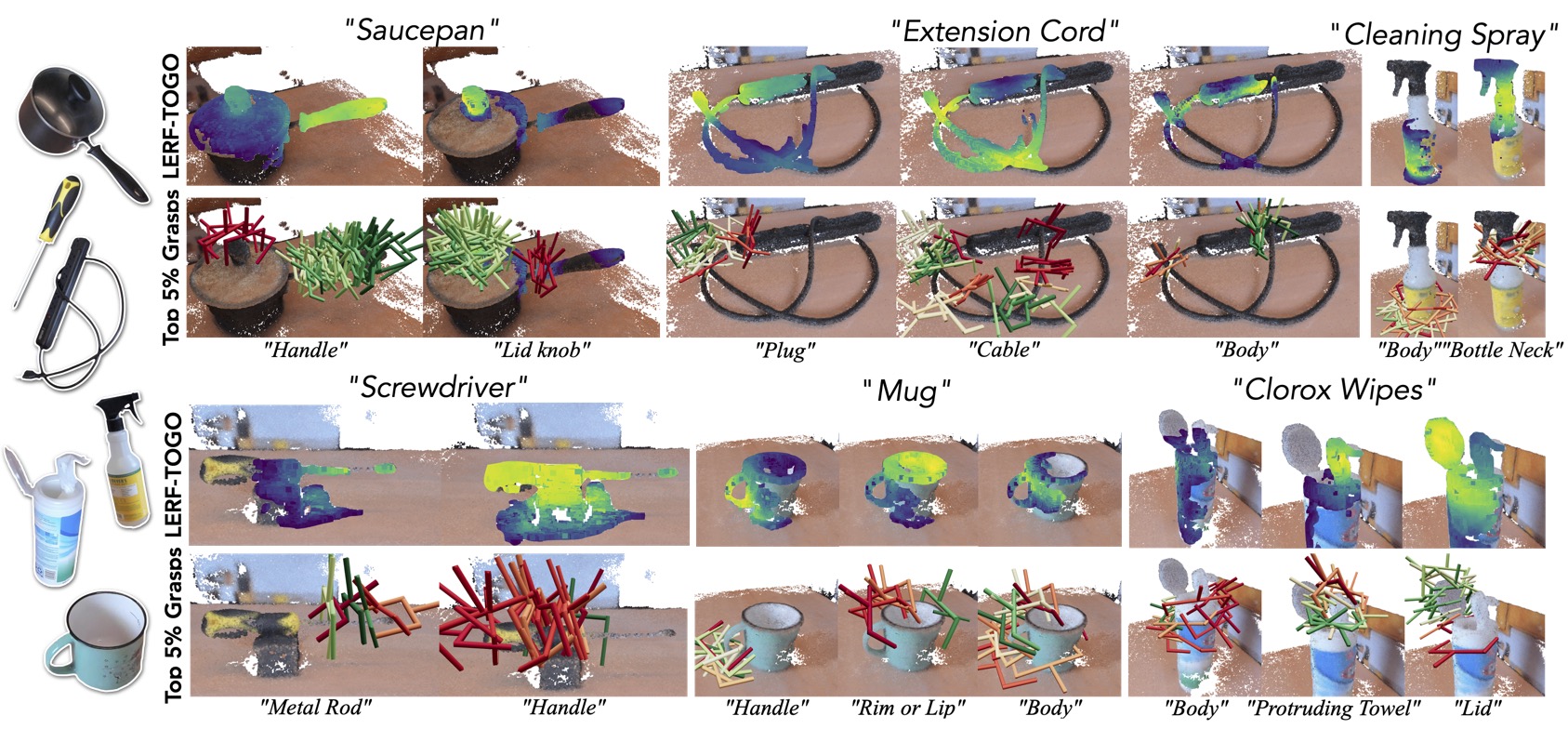
Why LERF?
LERF provides a dense, multi-scale 3D language field that can be queried zero-shot for long-tail objects. Since LERF is trained on multi-scale CLIP features, it can support more granular language queries like those of object parts. Similarly to LERF, Conceptfusion creates a dense, 3D language field, but it uses SAM masks which can struggle with granular queries.

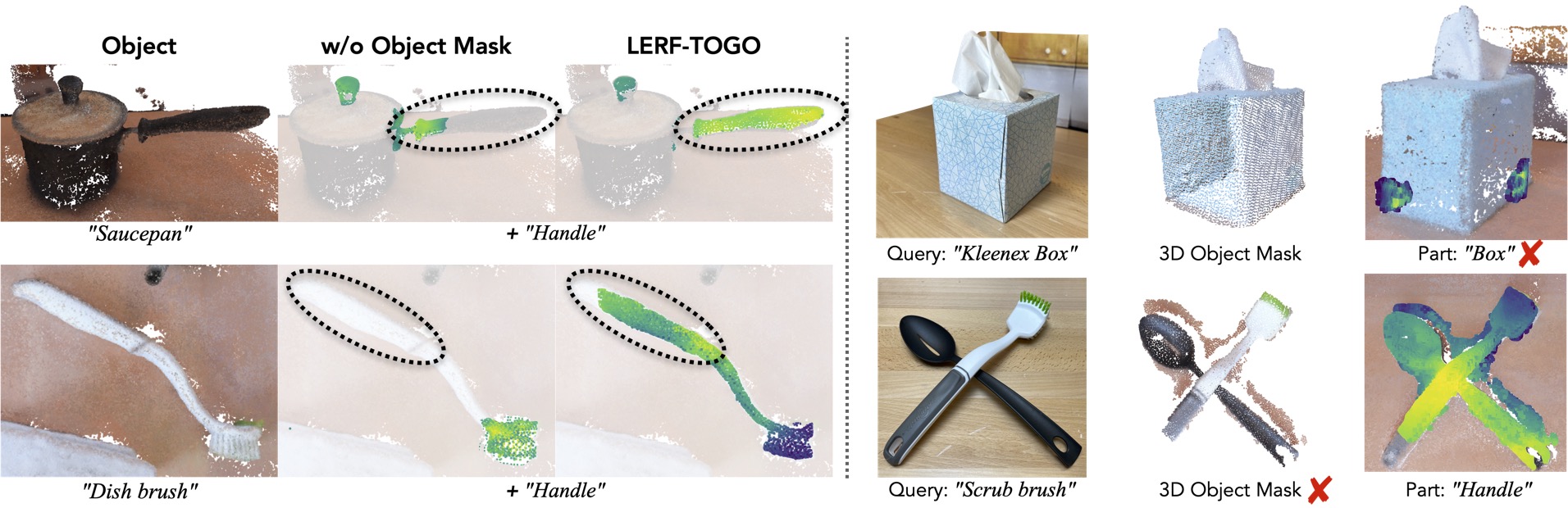
Why DINO?
LERF has no sense of objectness, meaning the activation maps returned by LERF are sometimes incomplete or don't respect the object's geometric boundaries. This is can problematic as the object of interest might not be activated in a way that allows for fine-tuned part queries. LERF-TOGO mitigates this lack of spatial grouping by extracting a 3D object mask via DINO features. This object mask provides a region in which we can search for the part query.
Citation
If you use this work or find it helpful, please consider citing: (bibtex)
@inproceedings{lerftogo2023,
title={Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping},
author={Adam Rashid and Satvik Sharma and Chung Min Kim and Justin Kerr and Lawrence Yunliang Chen and Angjoo Kanazawa and Ken Goldberg},
booktitle={7th Annual Conference on Robot Learning},
year={2023},
url={https://openreview.net/forum?id=k-Fg8JDQmc}
}